 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Object Detection
Papers and Code
Samba+: General and Accurate Salient Object Detection via A More Unified Mamba-based Framework
Feb 02, 2026Existing salient object detection (SOD) models are generally constrained by the limited receptive fields of convolutional neural networks (CNNs) and quadratic computational complexity of Transformers. Recently, the emerging state-space model, namely Mamba, has shown great potential in balancing global receptive fields and computational efficiency. As a solution, we propose Saliency Mamba (Samba), a pure Mamba-based architecture that flexibly handles various distinct SOD tasks, including RGB/RGB-D/RGB-T SOD, video SOD (VSOD), RGB-D VSOD, and visible-depth-thermal SOD. Specifically, we rethink the scanning strategy of Mamba for SOD, and introduce a saliency-guided Mamba block (SGMB) that features a spatial neighborhood scanning (SNS) algorithm to preserve the spatial continuity of salient regions. A context-aware upsampling (CAU) method is also proposed to promote hierarchical feature alignment and aggregation by modeling contextual dependencies. As one step further, to avoid the "task-specific" problem as in previous SOD solutions, we develop Samba+, which is empowered by training Samba in a multi-task joint manner, leading to a more unified and versatile model. Two crucial components that collaboratively tackle challenges encountered in input of arbitrary modalities and continual adaptation are investigated. Specifically, a hub-and-spoke graph attention (HGA) module facilitates adaptive cross-modal interactive fusion, and a modality-anchored continual learning (MACL) strategy alleviates inter-modal conflicts together with catastrophic forgetting. Extensive experiments demonstrate that Samba individually outperforms existing methods across six SOD tasks on 22 datasets with lower computational cost, whereas Samba+ achieves even superior results on these tasks and datasets by using a single trained versatile model. Additional results further demonstrate the potential of our Samba framework.
Breaking Alignment Barriers: TPS-Driven Semantic Correlation Learning for Alignment-Free RGB-T Salient Object Detection
Dec 26, 2025Existing RGB-T salient object detection methods predominantly rely on manually aligned and annotated datasets, struggling to handle real-world scenarios with raw, unaligned RGB-T image pairs. In practical applications, due to significant cross-modal disparities such as spatial misalignment, scale variations, and viewpoint shifts, the performance of current methods drastically deteriorates on unaligned datasets. To address this issue, we propose an efficient RGB-T SOD method for real-world unaligned image pairs, termed Thin-Plate Spline-driven Semantic Correlation Learning Network (TPS-SCL). We employ a dual-stream MobileViT as the encoder, combined with efficient Mamba scanning mechanisms, to effectively model correlations between the two modalities while maintaining low parameter counts and computational overhead. To suppress interference from redundant background information during alignment, we design a Semantic Correlation Constraint Module (SCCM) to hierarchically constrain salient features. Furthermore, we introduce a Thin-Plate Spline Alignment Module (TPSAM) to mitigate spatial discrepancies between modalities. Additionally, a Cross-Modal Correlation Module (CMCM) is incorporated to fully explore and integrate inter-modal dependencies, enhancing detection performance. Extensive experiments on various datasets demonstrate that TPS-SCL attains state-of-the-art (SOTA) performance among existing lightweight SOD methods and outperforms mainstream RGB-T SOD approaches.
Self-Explaining Hate Speech Detection with Moral Rationales
Jan 07, 2026Hate speech detection models rely on surface-level lexical features, increasing vulnerability to spurious correlations and limiting robustness, cultural contextualization, and interpretability. We propose Supervised Moral Rationale Attention (SMRA), the first self-explaining hate speech detection framework to incorporate moral rationales as direct supervision for attention alignment. Based on Moral Foundations Theory, SMRA aligns token-level attention with expert-annotated moral rationales, guiding models to attend to morally salient spans rather than spurious lexical patterns. Unlike prior rationale-supervised or post-hoc approaches, SMRA integrates moral rationale supervision directly into the training objective, producing inherently interpretable and contextualized explanations. To support our framework, we also introduce HateBRMoralXplain, a Brazilian Portuguese benchmark dataset annotated with hate labels, moral categories, token-level moral rationales, and socio-political metadata. Across binary hate speech detection and multi-label moral sentiment classification, SMRA consistently improves performance (e.g., +0.9 and +1.5 F1, respectively) while substantially enhancing explanation faithfulness, increasing IoU F1 (+7.4 pp) and Token F1 (+5.0 pp). Although explanations become more concise, sufficiency improves (+2.3 pp) and fairness remains stable, indicating more faithful rationales without performance or bias trade-offs
Salient Object Detection in Complex Weather Conditions via Noise Indicators
Dec 11, 2025Salient object detection (SOD), a foundational task in computer vision, has advanced from single-modal to multi-modal paradigms to enhance generalization. However, most existing SOD methods assume low-noise visual conditions, overlooking the degradation of segmentation accuracy caused by weather-induced noise in real-world scenarios. In this paper, we propose a SOD framework tailored for diverse weather conditions, encompassing a specific encoder and a replaceable decoder. To enable handling of varying weather noises, we introduce a one-hot vector as a noise indicator to represent different weather types and design a Noise Indicator Fusion Module (NIFM). The NIFM takes both semantic features and the noise indicator as dual inputs and is inserted between consecutive stages of the encoder to embed weather-aware priors via adaptive feature modulation. Critically, the proposed specific encoder retains compatibility with mainstream SOD decoders. Extensive experiments are conducted on the WXSOD dataset under varying training data scales (100%, 50%, 30% of the full training set), three encoder and seven decoder configurations. Results show that the proposed SOD framework (particularly the NIFM-enhanced specific encoder) improves segmentation accuracy under complex weather conditions compared to a vanilla encoder.
Assisted Refinement Network Based on Channel Information Interaction for Camouflaged and Salient Object Detection
Dec 12, 2025Camouflaged Object Detection (COD) stands as a significant challenge in computer vision, dedicated to identifying and segmenting objects visually highly integrated with their backgrounds. Current mainstream methods have made progress in cross-layer feature fusion, but two critical issues persist during the decoding stage. The first is insufficient cross-channel information interaction within the same-layer features, limiting feature expressiveness. The second is the inability to effectively co-model boundary and region information, making it difficult to accurately reconstruct complete regions and sharp boundaries of objects. To address the first issue, we propose the Channel Information Interaction Module (CIIM), which introduces a horizontal-vertical integration mechanism in the channel dimension. This module performs feature reorganization and interaction across channels to effectively capture complementary cross-channel information. To address the second issue, we construct a collaborative decoding architecture guided by prior knowledge. This architecture generates boundary priors and object localization maps through Boundary Extraction (BE) and Region Extraction (RE) modules, then employs hybrid attention to collaboratively calibrate decoded features, effectively overcoming semantic ambiguity and imprecise boundaries. Additionally, the Multi-scale Enhancement (MSE) module enriches contextual feature representations. Extensive experiments on four COD benchmark datasets validate the effectiveness and state-of-the-art performance of the proposed model. We further transferred our model to the Salient Object Detection (SOD) task and demonstrated its adaptability across downstream tasks, including polyp segmentation, transparent object detection, and industrial and road defect detection. Code and experimental results are publicly available at: https://github.com/akuan1234/ARNet-v2.
FocalComm: Hard Instance-Aware Multi-Agent Perception
Dec 20, 2025
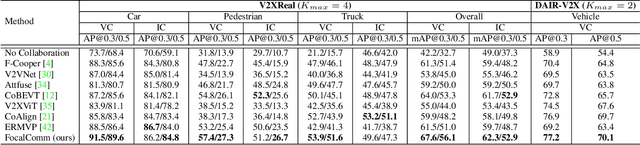


Multi-agent collaborative perception (CP) is a promising paradigm for improving autonomous driving safety, particularly for vulnerable road users like pedestrians, via robust 3D perception. However, existing CP approaches often optimize for vehicle detection performance metrics, underperforming on smaller, safety-critical objects such as pedestrians, where detection failures can be catastrophic. Furthermore, previous CP methods rely on full feature exchange rather than communicating only salient features that help reduce false negatives. To this end, we present FocalComm, a novel collaborative perception framework that focuses on exchanging hard-instance-oriented features among connected collaborative agents. FocalComm consists of two key novel designs: (1) a learnable progressive hard instance mining (HIM) module to extract hard instance-oriented features per agent, and (2) a query-based feature-level (intermediate) fusion technique that dynamically weights these identified features during collaboration. We show that FocalComm outperforms state-of-the-art collaborative perception methods on two challenging real-world datasets (V2X-Real and DAIR-V2X) across both vehicle-centric and infrastructure-centric collaborative setups. FocalComm also shows a strong performance gain in pedestrian detection in V2X-Real.
Content-Aware Ad Banner Layout Generation with Two-Stage Chain-of-Thought in Vision Language Models
Dec 14, 2025In this paper, we propose a method for generating layouts for image-based advertisements by leveraging a Vision-Language Model (VLM). Conventional advertisement layout techniques have predominantly relied on saliency mapping to detect salient regions within a background image, but such approaches often fail to fully account for the image's detailed composition and semantic content. To overcome this limitation, our method harnesses a VLM to recognize the products and other elements depicted in the background and to inform the placement of text and logos. The proposed layout-generation pipeline consists of two steps. In the first step, the VLM analyzes the image to identify object types and their spatial relationships, then produces a text-based "placement plan" based on this analysis. In the second step, that plan is rendered into the final layout by generating HTML-format code. We validated the effectiveness of our approach through evaluation experiments, conducting both quantitative and qualitative comparisons against existing methods. The results demonstrate that by explicitly considering the background image's content, our method produces noticeably higher-quality advertisement layouts.
SAM-DAQ: Segment Anything Model with Depth-guided Adaptive Queries for RGB-D Video Salient Object Detection
Nov 13, 2025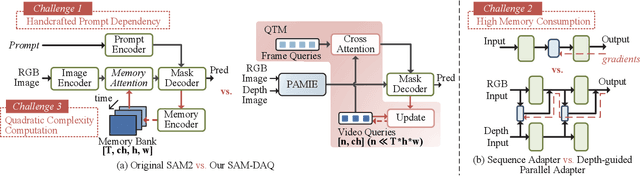
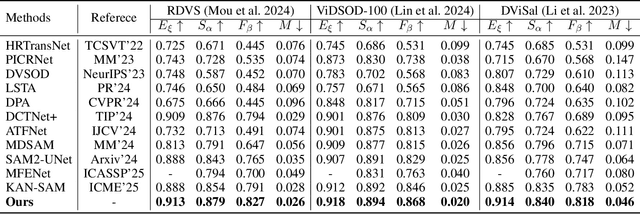
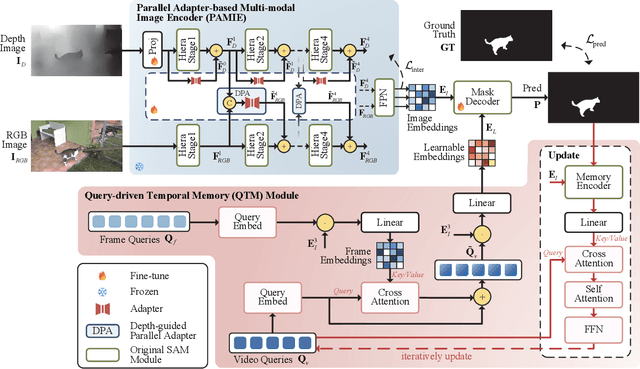
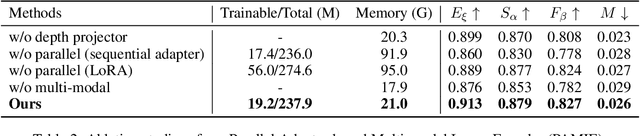
Recently segment anything model (SAM) has attracted widespread concerns, and it is often treated as a vision foundation model for universal segmentation. Some researchers have attempted to directly apply the foundation model to the RGB-D video salient object detection (RGB-D VSOD) task, which often encounters three challenges, including the dependence on manual prompts, the high memory consumption of sequential adapters, and the computational burden of memory attention. To address the limitations, we propose a novel method, namely Segment Anything Model with Depth-guided Adaptive Queries (SAM-DAQ), which adapts SAM2 to pop-out salient objects from videos by seamlessly integrating depth and temporal cues within a unified framework. Firstly, we deploy a parallel adapter-based multi-modal image encoder (PAMIE), which incorporates several depth-guided parallel adapters (DPAs) in a skip-connection way. Remarkably, we fine-tune the frozen SAM encoder under prompt-free conditions, where the DPA utilizes depth cues to facilitate the fusion of multi-modal features. Secondly, we deploy a query-driven temporal memory (QTM) module, which unifies the memory bank and prompt embeddings into a learnable pipeline. Concretely, by leveraging both frame-level queries and video-level queries simultaneously, the QTM module can not only selectively extract temporal consistency features but also iteratively update the temporal representations of the queries. Extensive experiments are conducted on three RGB-D VSOD datasets, and the results show that the proposed SAM-DAQ consistently outperforms state-of-the-art methods in terms of all evaluation metrics.
Using Salient Object Detection to Identify Manipulative Cookie Banners that Circumvent GDPR
Oct 30, 2025The main goal of this paper is to study how often cookie banners that comply with the General Data Protection Regulation (GDPR) contain aesthetic manipulation, a design tactic to draw users' attention to the button that permits personal data sharing. As a byproduct of this goal, we also evaluate how frequently the banners comply with GDPR and the recommendations of national data protection authorities regarding banner designs. We visited 2,579 websites and identified the type of cookie banner implemented. Although 45% of the relevant websites have fully compliant banners, we found aesthetic manipulation on 38% of the compliant banners. Unlike prior studies of aesthetic manipulation, we use a computer vision model for salient object detection to measure how salient (i.e., attention-drawing) each banner element is. This enables the discovery of new types of aesthetic manipulation (e.g., button placement), and leads us to conclude that aesthetic manipulation is more common than previously reported (38% vs 27% of banners). To study the effects of user and/or website location on cookie banner design, we include websites within the European Union (EU), where privacy regulation enforcement is more stringent, and websites outside the EU. We visited websites from IP addresses in the EU and from IP addresses in the United States (US). We find that 13.9% of EU websites change their banner design when the user is from the US, and EU websites are roughly 48.3% more likely to use aesthetic manipulation than non-EU websites, highlighting their innovative responses to privacy regulation.
S3OD: Towards Generalizable Salient Object Detection with Synthetic Data
Oct 24, 2025Salient object detection exemplifies data-bounded tasks where expensive pixel-precise annotations force separate model training for related subtasks like DIS and HR-SOD. We present a method that dramatically improves generalization through large-scale synthetic data generation and ambiguity-aware architecture. We introduce S3OD, a dataset of over 139,000 high-resolution images created through our multi-modal diffusion pipeline that extracts labels from diffusion and DINO-v3 features. The iterative generation framework prioritizes challenging categories based on model performance. We propose a streamlined multi-mask decoder that naturally handles the inherent ambiguity in salient object detection by predicting multiple valid interpretations. Models trained solely on synthetic data achieve 20-50% error reduction in cross-dataset generalization, while fine-tuned versions reach state-of-the-art performance across DIS and HR-SOD benchmarks.